

I’ve started encountering a problem that I should use some assistance troubleshooting. I’ve got a Proxmox system that hosts, primarily, my Opnsense router. I’ve had this specific setup for about a year.
Recently, I’ve been experiencing sluggishness and noticed that the IO wait is through the roof. Rebooting the Opnsense VM, which normally only takes a few minutes is now taking upwards of 15-20. The entire time my IO wait sits between 50-80%.
The system has 1 disk in it that is formatted ZFS. I’ve checked dmesg, and the syslog for indications of disk errors (this feels like a failing disk) and found none. I also checked the smart statistics and they all “PASSED”.
Any pointers would be appreciated.
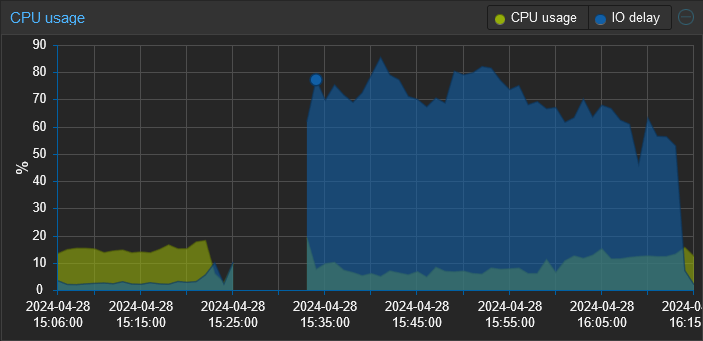
Edit: I believe I’ve found the root cause of the change in performance and it was a bit of shooting myself in the foot. I’ve been experimenting with different tools for log collection and the most recent one is a SIEM tool called Wazuh. I didn’t realize that upon reboot it runs an integrity check that generates a ton of disk I/O. So when I rebooted this proxmox server, that integrity check was running on proxmox, my pihole, and (I think) opnsense concurrently. All against a single consumer grade HDD.
Thanks to everyone who responded. I really appreciate all the performance tuning guidance. I’ve also made the following changes:
- Added a 2nd drive (I have several of these lying around, don’t ask) converting the zfs pool into a mirror. This gives me both redundancy and should improve read performance.
- Configured a 2nd storage target on the same zpool with compression enabled and a 64k block size in proxmox. I then migrated the 2 VMs to that storage.
- Since I’m collecting logs in Wazuh I set Opnsense to use ram disks for /tmp and /var/log.
Rebooted Opensense and it was back up in 1:42 min.
You must log in or register to comment.
There was a recent conversation on the Practical ZFS discourse site about poor disk performance in Proxmox (https://discourse.practicalzfs.com/t/hard-drives-in-zfs-pool-constantly-seeking-every-second/1421/). Not sure if you’re seeing the same thing, but it could be that your VMs are running into the same too-small
volblocksizethat PVE uses to make zvols for its Vans under ZFS.If that’s the case, the solution is pretty easy. In your PVE datacenter view, go to storage and create a new ZFS storage pool. Point it to the same zpool/dataset as the one you’ve already got and set the block size to something like 32k or 64k. Once you’ve done that, move the VM’s disk to that new storage pool.
Like I said, not sure if you’re seeing the same issue, but it’s a simple thing to try.
This was really interesting, thanks for the info.
iowait is indicative of storage not being able to keep up with the performance of the rest of the system. What hardware are you using for storage here?
It’s an old Optiplex SFF with a single HDD. Again, my concern isn’t that it’s “slow”. It’s that performance has rather suddenly tanked and the only changes I’ve made are regular OS updates.
If I had to guess there was a code change in the PVE kernel or in their integrated ZFS module that led to a performance regression for your use case. I don’t really have any feedback there, PVE ships a modified version of an older kernel (6.2?) so something could have been backported into that tree that led to the regression. Same deal with ZFS, whichever version the PVE folks are shipping could have introduced a regression as well.
Your best bet is to raise an issue with the PVE folks after identifying which kernel version introduced the regression, you’ll want to do a binary search between now and the last known good time that this wasn’t occurring to determine exactly when the issue started - then you can open an issue describing the regression.
Or just throw a cheap SSD at the problem and move on, that’s what I’d do here. Something like this should outlast the machine you put it in.
Edit: the Samsung 863a also pops up cheaply from time to time, it has good endurance and PLP. Basically just search fleaBay for SATA drives with capacities of 400/480gb, 800/960gb, 1.6T/1.92T or 3.2T/3.84T and check their datasheets for endurance info and PLP capability. Anything in the 400/800/1600/3200Gb sequence is a model with more overprovisioning and higher endurance (usually refered to as mixed use) model. Those often have 3 DWPD or 5 DWPD ratings and are a safe bet if you have a write heavy workload.
I thought cheap SSDs and ZFS didn’t play well together?
Depends on the SSD, the one I linked is fine for casual home server use. You’re unlikely to see enough of a write workload that endurance will be an issue. That’s an enterprise drive btw, it certainly wasn’t cheap when it was brand new and I doubt running a couple of VMs will wear it quickly. (I’ve had a few of those in service at home for 3-4y, no problems.)
Consumer drives have more issues, their write endurance is considerably lower than most enterprise parts. You can blow through a cheap consumer SSD’s endurance in mere months with a hypervisor workload so I’d strongly recommend using enterprise drives where possible.
It’s always worth taking a look at drive datasheets when you’re considering them and comparing the warranty lifespan to your expected usage too. The drive linked above has an expected endurance of like 2PB (~3 DWPD, OR 2TB/day, over 3y) so you shouldn’t have any problems there. See https://www.sandisk.com/content/dam/sandisk-main/en_us/assets/resources/enterprise/data-sheets/cloudspeed-eco-genII-sata-ssd-datasheet.pdf
Older gen retired or old stock parts are basically the only way I buy home server storage now, the value for your money is tremendous and most drives are lightly used at most.
Edit: some select consumer SSDs can work fairly well with ZFS too, but they tend to be higher endurance parts with more baked in over provisioning. It was popular to use Samsung 850 or 860 Pros for a while due to their tremendous endurance (the 512GB 850s often had an endurance lifespan of like 10PB+ before failure thanks to good old high endurance MLC flash) but it’s a lot safer to just buy retired enterprise parts now that they’re available cheaply. There are some gotchas that come along with using high endurance consumer drives, like poor sync write performance due to lack of PLP, but you’ll still see far better performance than an HDD.
Thanks for all the info. I’ll keep this in mind if I replace the drive. I am using refurb enterprise HDDs in my main server. Didn’t think I’d need to go enterprise grade for this box but you make a lot of sense.
Keep in mind it’s more an issue with writes as others mentioned when it comes to ssds. I use two ssds in a zfs mirror that I installed proxmox directly on. It’s an option in the installer and it’s quite nice.
As for combating writes that’s actually easier than you think and applies to any filesystem. It just takes knowing what is write intensive. Most of the time for a linux os like proxmox that’s going to be temp files and logs. Both of which can easily be migrated to tmpfs. Doing this will increase the lifespan of any ssd dramatically. You just have to understand restarting clears those locations because now they exist in ram.
As I mentioned elsewhere opnsense has an option within the gui to migrate tmp files to memory.
Quick and easy fix attempt would be to replace the HDD with an SSD. As others have said, the drive may just be failing. Replacing with an SSD would not only get rid of the suspect hardware, but would be an upgrade to boot. You can clone the drive, or just start fresh with the backups you have.
I may end up having to go that route. I’m no expert but aren’t you supposed to use different parameters when using SSDs on ZFS vs an HDD?
That’s what I’d do here, used enterprise SSDs are dirt cheap on fleaBay
It could be a disk slowly failing but not throwing errors yet. Some drives really do their best to hide that they’re failing. So even a passing SMART test I would take with some salt.
I would start by making sure you have good recent backups ASAP.
You can test the drive performance by shutting down all VMs and using tools like fio to do some disk benchmarking. It could be a VM causing it. If it’s an HDD in particular, the random reads and writes from VMs can really cause seek latency to shoot way up. Could be as simple as a service logging some warnings due to junk incoming traffic, or an update that added some more info logs, etc.
I would start by making sure you have good recent backups ASAP.
I do.
Could be as simple as a service logging some warnings due to junk incoming traffic, or an update that added some more info logs, etc.
Possible. It’s a really consistent (and stark) degradation in performance tho and is repeatable even when the opnsense VM is the only one running.
Check the ZFS pool status. You could lots of errors that ZFS is correcting.
I’m starting to lean towards this being an I/O issue but I haven’t figure out what or why yet. I don’t often make changes to this environment since it’s running my Opnsens router.
root@proxmox-02:~# zpool status pool: rpool state: ONLINE status: Some supported and requested features are not enabled on the pool. The pool can still be used, but some features are unavailable. action: Enable all features using 'zpool upgrade'. Once this is done, the pool may no longer be accessible by software that does not support the features. See zpool-features(7) for details. scan: scrub repaired 0B in 00:56:10 with 0 errors on Sun Apr 28 17:24:59 2024 config: NAME STATE READ WRITE CKSUM rpool ONLINE 0 0 0 ata-ST500LM021-1KJ152_W62HRJ1A-part3 ONLINE 0 0 0 errors: No known data errorsIt looks like you could also do a zpool upgrade. This will just upgrade your legacy pools to the newer zfs version. That command is fairly simple to run from terminal if you are already examining the pool.
Edit
Btw if you have ran pve updates it may be expecting some newer zfs flags for your pool. A pool upgrade may resolve the issue enabling the new features.
I’ve done a bit of research on that and I believe upgrading the zpool would make my system unbootable.
Upgrading a ZFS pool itself shouldn’t make a system unbootable even if an rpool (root pool) exists on it.
That could only happen if the upgrade took a shit during a power outage or something like that. The upgrade itself usually only takes a few seconds from the command line.
If it makes you feel better I upgraded mine with an rpool on it and it was painless. I do have a everything backed up tho so I rarely worry. However ai understand being hesitant.
I’m referring to this.
… using grub to directly boot from ZFS - such setups are in general not safe to run zpool upgrade on!
$ sudo proxmox-boot-tool status Re-executing '/usr/sbin/proxmox-boot-tool' in new private mount namespace.. System currently booted with legacy bios 8357-FBD5 is configured with: grub (versions: 6.5.11-7-pve, 6.5.13-5-pve, 6.8.4-2-pve)Unless I’m misunderstanding the guidance.
It looks like you are using legacy bios. mine is using uefi with a zfs rpool
proxmox-boot-tool status Re-executing '/usr/sbin/proxmox-boot-tool' in new private mount namespace.. System currently booted with uefi 31FA-87E2 is configured with: uefi (versions: 6.5.11-8-pve, 6.5.13-5-pve)However, like with everything a method always exists to get it done. Or not if you are concerned.
If you are interested it would look like…
Pool Upgrade
sudo zpool upgrade <pool_name>Confirm Upgrade
sudo zpool statusRefresh boot config
sudo pveboot-tool refreshConfirm Boot configuration
cat /boot/grub/grub.cfgYou are looking for directives like this to see if they are indeed pointing at your existing rpool
root=ZFS=rpool/ROOT/pve-1 boot=zfs quiethere is my file if it helps you compare…
# # DO NOT EDIT THIS FILE # # It is automatically generated by grub-mkconfig using templates # from /etc/grub.d and settings from /etc/default/grub # ### BEGIN /etc/grub.d/000_proxmox_boot_header ### # # This system is booted via proxmox-boot-tool! The grub-config used when # booting from the disks configured with proxmox-boot-tool resides on the vfat # partitions with UUIDs listed in /etc/kernel/proxmox-boot-uuids. # /boot/grub/grub.cfg is NOT read when booting from those disk! ### END /etc/grub.d/000_proxmox_boot_header ### ### BEGIN /etc/grub.d/00_header ### if [ -s $prefix/grubenv ]; then set have_grubenv=true load_env fi if [ "${next_entry}" ] ; then set default="${next_entry}" set next_entry= save_env next_entry set boot_once=true else set default="0" fi if [ x"${feature_menuentry_id}" = xy ]; then menuentry_id_option="--id" else menuentry_id_option="" fi export menuentry_id_option if [ "${prev_saved_entry}" ]; then set saved_entry="${prev_saved_entry}" save_env saved_entry set prev_saved_entry= save_env prev_saved_entry set boot_once=true fi function savedefault { if [ -z "${boot_once}" ]; then saved_entry="${chosen}" save_env saved_entry fi } function load_video { if [ x$feature_all_video_module = xy ]; then insmod all_video else insmod efi_gop insmod efi_uga insmod ieee1275_fb insmod vbe insmod vga insmod video_bochs insmod video_cirrus fi } if loadfont unicode ; then set gfxmode=auto load_video insmod gfxterm set locale_dir=$prefix/locale set lang=en_US insmod gettext fi terminal_output gfxterm if [ "${recordfail}" = 1 ] ; then set timeout=30 else if [ x$feature_timeout_style = xy ] ; then set timeout_style=menu set timeout=5 # Fallback normal timeout code in case the timeout_style feature is # unavailable. else set timeout=5 fi fi ### END /etc/grub.d/00_header ### ### BEGIN /etc/grub.d/05_debian_theme ### set menu_color_normal=cyan/blue set menu_color_highlight=white/blue ### END /etc/grub.d/05_debian_theme ### ### BEGIN /etc/grub.d/10_linux ### function gfxmode { set gfxpayload="${1}" } set linux_gfx_mode= export linux_gfx_mode menuentry 'Proxmox VE GNU/Linux' --class proxmox --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-/dev/sdc3' { load_video insmod gzio if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi insmod part_gpt echo 'Loading Linux 6.5.13-5-pve ...' linux /ROOT/pve-1@/boot/vmlinuz-6.5.13-5-pve root=ZFS=/ROOT/pve-1 ro root=ZFS=rpool/ROOT/pve-1 boot=zfs quiet echo 'Loading initial ramdisk ...' initrd /ROOT/pve-1@/boot/initrd.img-6.5.13-5-pve } submenu 'Advanced options for Proxmox VE GNU/Linux' $menuentry_id_option 'gnulinux-advanced-/dev/sdc3' { menuentry 'Proxmox VE GNU/Linux, with Linux 6.5.13-5-pve' --class proxmox --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-6.5.13-5-pve-advanced-/dev/sdc3' { load_video insmod gzio if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi insmod part_gpt echo 'Loading Linux 6.5.13-5-pve ...' linux /ROOT/pve-1@/boot/vmlinuz-6.5.13-5-pve root=ZFS=/ROOT/pve-1 ro root=ZFS=rpool/ROOT/pve-1 boot=zfs quiet echo 'Loading initial ramdisk ...' initrd /ROOT/pve-1@/boot/initrd.img-6.5.13-5-pve } menuentry 'Proxmox VE GNU/Linux, with Linux 6.5.13-5-pve (recovery mode)' --class proxmox --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-6.5.13-5-pve-recovery-/dev/sdc3' { load_video insmod gzio if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi insmod part_gpt echo 'Loading Linux 6.5.13-5-pve ...' linux /ROOT/pve-1@/boot/vmlinuz-6.5.13-5-pve root=ZFS=/ROOT/pve-1 ro single root=ZFS=rpool/ROOT/pve-1 boot=zfs echo 'Loading initial ramdisk ...' initrd /ROOT/pve-1@/boot/initrd.img-6.5.13-5-pve } menuentry 'Proxmox VE GNU/Linux, with Linux 6.5.11-8-pve' --class proxmox --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-6.5.11-8-pve-advanced-/dev/sdc3' { load_video insmod gzio if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi insmod part_gpt echo 'Loading Linux 6.5.11-8-pve ...' linux /ROOT/pve-1@/boot/vmlinuz-6.5.11-8-pve root=ZFS=/ROOT/pve-1 ro root=ZFS=rpool/ROOT/pve-1 boot=zfs quiet echo 'Loading initial ramdisk ...' initrd /ROOT/pve-1@/boot/initrd.img-6.5.11-8-pve } menuentry 'Proxmox VE GNU/Linux, with Linux 6.5.11-8-pve (recovery mode)' --class proxmox --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-6.5.11-8-pve-recovery-/dev/sdc3' { load_video insmod gzio if [ x$grub_platform = xxen ]; then insmod xzio; insmod lzopio; fi insmod part_gpt echo 'Loading Linux 6.5.11-8-pve ...' linux /ROOT/pve-1@/boot/vmlinuz-6.5.11-8-pve root=ZFS=/ROOT/pve-1 ro single root=ZFS=rpool/ROOT/pve-1 boot=zfs echo 'Loading initial ramdisk ...' initrd /ROOT/pve-1@/boot/initrd.img-6.5.11-8-pve } } ### END /etc/grub.d/10_linux ### ### BEGIN /etc/grub.d/20_linux_xen ### ### END /etc/grub.d/20_linux_xen ### ### BEGIN /etc/grub.d/20_memtest86+ ### ### END /etc/grub.d/20_memtest86+ ### ### BEGIN /etc/grub.d/30_os-prober ### ### END /etc/grub.d/30_os-prober ### ### BEGIN /etc/grub.d/30_uefi-firmware ### menuentry 'UEFI Firmware Settings' $menuentry_id_option 'uefi-firmware' { fwsetup } ### END /etc/grub.d/30_uefi-firmware ### ### BEGIN /etc/grub.d/40_custom ### # This file provides an easy way to add custom menu entries. Simply type the # menu entries you want to add after this comment. Be careful not to change # the 'exec tail' line above. ### END /etc/grub.d/40_custom ### ### BEGIN /etc/grub.d/41_custom ### if [ -f ${config_directory}/custom.cfg ]; then source ${config_directory}/custom.cfg elif [ -z "${config_directory}" -a -f $prefix/custom.cfg ]; then source $prefix/custom.cfg fi ### END /etc/grub.d/41_custom ###You can see the lines by the linux sections.
Thanks I may give it a try if I’m feeling daring.
(If it’s not failing, which would be the first thing I’d check)
Do you have any new VMs up and running. IO was the bane of my existence with proxmox, but realized it’s just that VMs eat a ton of IO, especially with ZFS. A standard HDD won’t cut it (unless you have one and only one VM using that disk). Even sata SSDs just didn’t cut it over time, I had to build a full raid that would support 5-10 VMs on it before I saw IO wait drop enough.
I’m trying to think of anything I may have changed since the last time I rebooted the opnsense VM. But I try to keep up on updates and end up rebooting pretty regularly. The only things on this system are the opnsense VM and a small pihole VM. At the time of the screenshot above, the opnsense VM was the only thing running.
If it’s not a failing HDD, my next step is to try and dig into what’s generating the I/O to see if there’s something misbehaving.
I had bad luck with ZFS on proxmox because of all of the overhead, I found with my tiny cluster it was better to do good old ext4 and then just do regular backups. ZFS actually killed quite a few of my drives because of it’s heavyweight. Not saying that’s your problem, but I wouldn’t be surprised if it was
Did you do a smart test?
Short test completed without error.
Kinda feel dumb that my answer is no. Let me do that and report back.
While you’re waiting for that, I’d also look at the smart data and write the output to a file, then check it again later to see if any of the numbers have changed, especially reallocated sectors, pending sectors, corrected and uncorrected errors, stuff like that.
Actually, I’m pretty sure that Proxmox will notify you of certain smart issues if you have emails configured.
You should also shut the host down and reseat the drives, and check the cables to make sure they’re all properly seated too. It’s possible that one has come loose but not enough to drop the link.
While you’re waiting for that, I’d also look at the smart data and write the output to a file, then check it again later to see if any of the numbers have changed, especially reallocated sectors, pending sectors, corrected and uncorrected errors, stuff like that.
That’s a good idea. Thanks.
Run long smart test on the disk and check smart data after that. Other possibility is ZFS pool is nearly full.
Sounds like a hardware issue. I would also check dmesg and journalctl
Out of curiosity what filesystem did you choose for you opnsense vm. Also can you tell if it’s a zvol, qcow2, or raw disk. FYI if it’s a qcow2 or a raw they both would benefit from a record size of 64k if they exist in a vm dataset. If it’s a zvol still 64 k can help.
I also utilize a heavily optimized setup running opnsense within proxmox. My vm filesystem is ufs because it’s on top of proxmox zfs. You can always find some settings in your opnsense vm to migrate log files to tmpfs which places them in memory. That will heavily reduce disk writes from opnsense.
Proxmox is using ZFS. Opnsense is using UFS. Regarding the record size I assume you’re referring to the same thing this comment is?
You can always find some settings in your opnsense vm to migrate log files to tmpfs which places them in memory.
I’ll look into this.
I’m specifically referencing this little bit of info for optimizing zfs for various situations.
Vms for example should exist in their own dataset with a tuned record size of 64k
Media should exist in its own with a tuned record size of 1mb
lz4 is quick and should always be enabled. It will also work efficiently with larger record sizes.
Anyway all the little things add up with zfs. When you have an underlying zfs you can get away with more simple and performant filesystems on zvols or qcow2. XFS, UFS, EXT4 all work well with 64k record sizes from the underlying zfs dataset/zvol.
Btw it doesn’t change immediately on existing data if you just change the option on a dataset. You have to move the data out then back in for it to have the new record size.
That cheat sheet is getting bookmarked. Thanks.
You are very welcome :)
Media should exist in its own with a tuned record size of 1mb
Should the vm storage block size also be set to 1MB or just the ZFS record size?
most filesystems as mentioned in the guide that exist within qcow2, zvols, even raws, that live on a zfs dataset would benefit form a zfs recordsize of 64k. By default the recordsize will be 128k.
I would never utilize 1mb for any dataset that had vm disks inside it.
I would create a new dataset for media off the pool and set a recordsize of 1mb. You can only really get away with this if you have media files directly inside this dataset. So pics, music, videos.
The cool thing is you can set these options on an individual dataset basis. so one dataset can have one recordsize and another dataset can have another.






