
Hello everyone, we’re long overdue for an update on how things have been going!
Finances
Since we started accepting donations back in July we’ve received a total of $1350, as well as $1707 in older donations from smorks. We haven’t had any expenses other than OVH (approx $155/mo) since then, leaving us $2152 in the bank.
We still owe TruckBC $1980 for the period he was covering hosting, and I’ve contributed $525 as well (mostly non-profit registration related stuff, plus domain renewals). We haven’t yet discussed reimbursing either of us, we’re both happy to build up a contingency fund for a while.
New Server
A few weeks ago, we experienced a ~26-hour outage due to a failed power supply and extremely slow response times from OVH support. This was followed by an unexplained outage the next morning at the same time. To ensure Lemmy’s growth remains sustainable for the long term and to support other federated applications, I’ve donated a new physical server. This will give us a significant boost in resources while keeping the monthly cost increase minimal.
Our system specs today:
- Undoubtedly the cheapest hardware OVH could buy
- Intel Xeon E-2386G (6 cores @ 3.5ghz)
- 32gb of ram
- 2x 512gb Samsung nvme in raid 1
- 1gb network
- $155/month
The new system:
- Dell R7525
- AMD EPYC 7763 (64 cores @ 2.45ghz)
- 1tb of ram
- 3x 120gb sata ssd (hw raid 1 with a hot spare, for proxmox)
- 4x 6.4tb nvme (zfs mirrored + striped, for data)
- 1gb network with a 50mbit commit (See 95th percentile billing)
- Redundant power supplies
- Next day hardware support until Aug 2027
- $166/month + tax
This means instead of renting an entire server and having them be responsible for the hardware, we’ll be renting co-location space at a Vancouver datacenter PDF via a 3rd party service provider I know.
These servers are extremely reliable but if there is a failure, either Otter or myself will be able to get access reasonably quickly. We also have full OOB access via idrac, so it’s pretty unlikely we’ll ever need to go on site.
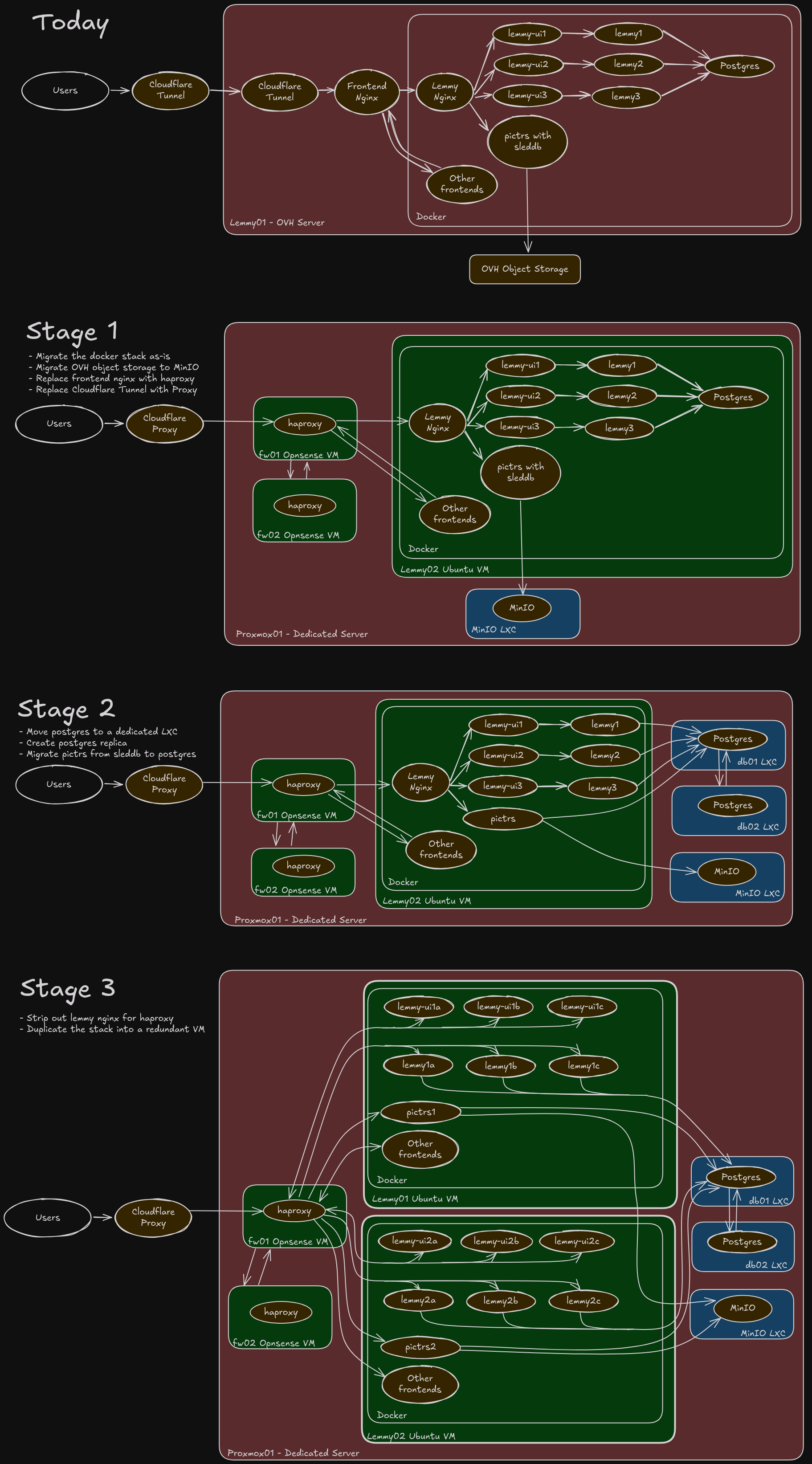
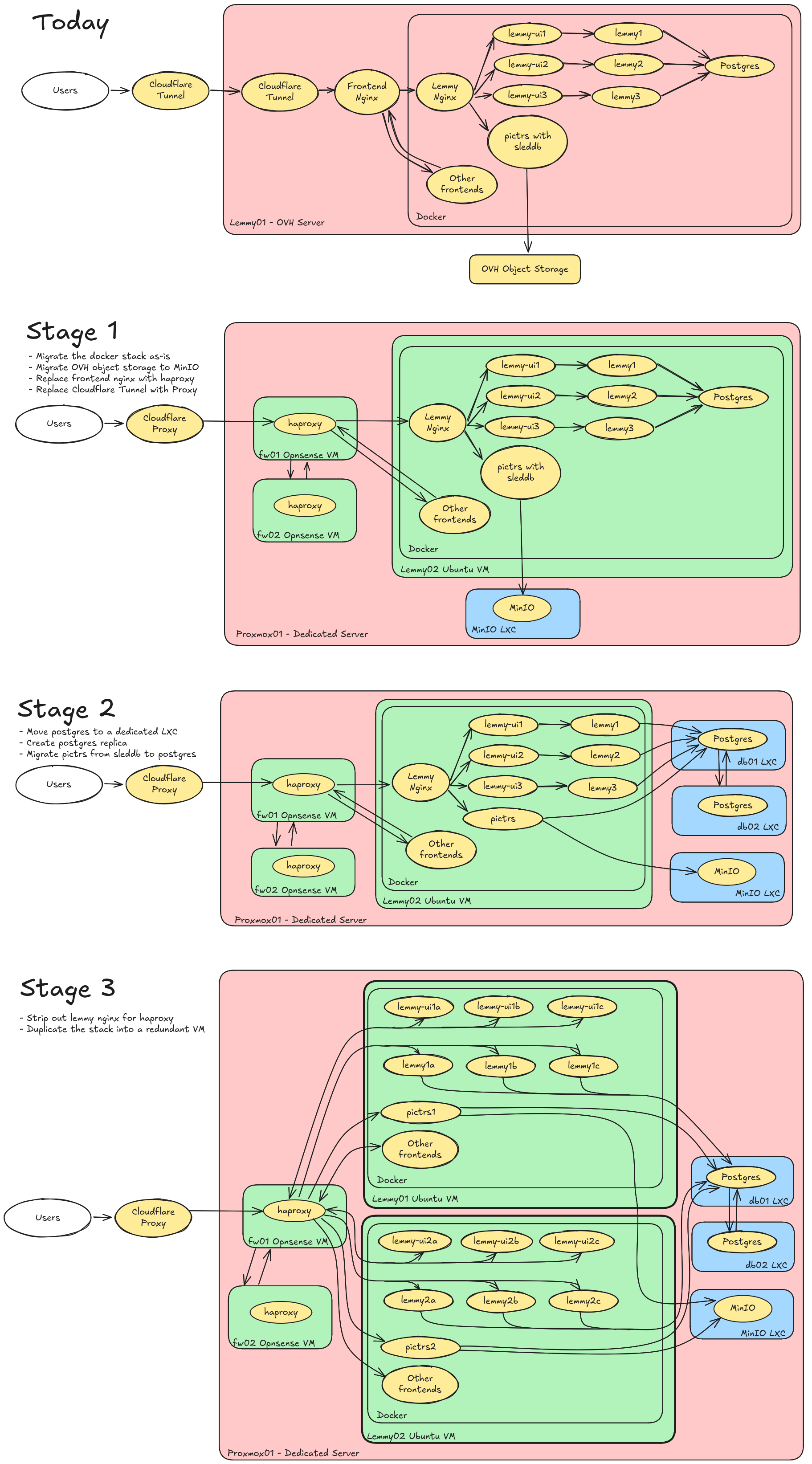
Server Migration
Phase 1 is currently planned for Jan 29th or 30th and will completely move us out of OVH and onto our own hardware. I’m expecting probably a 2-3 hour outage, followed by an 6-8 hour window where some images may be missing as the object store resyncs. I’ll make another follow up post in a week with specifics.
Phases 2+ I’m not 100% decided on yet and have not planned a timeline around. It would get us into a fully redundant (excluding hardware) setup that’s easier to scale and manage down the road, but it does add a little bit of complexity.
Let me know if you have any questions or comments, or feedback on the architecture!
You must log in or register to comment.
That’s quite a beefy machine.
Nice to know things are chugging along nicely.
I’m always so glad that this is the instance I chose to join in the Great Migration, and equally glad that I’ve been welcome here. Keep up the awesome work and thank you for keeping the communication so open.
Wow that’s one fat machine. I like it!
Thank you for the continued support! I can see our monthly donations are used well. ☺️
What a machine to donate! Thanks!
I donated for a couple months, and had to stop due to personal finances, hope tos tart again soon
Thanks for all that you do, and the great communication!
I’m seeing a net debt of about $400 hanging over you guys after all is said and done. I don’t think anyone is clamoring for that money to be paid back, but I’d be happier if you guys didn’t have to worry about it. I’ll send some money for that reason, as well as all the good work you all do in supporting and maintaining this. Thank you.
Thanks, appreciate this and all the other donations I’ve seen in the past day!
If you are ok with saying, how much did that server cost?
When purchased brand new by a now dying tech company, it was about 20-25k. I put dibs on it as part of my commission for managing the shut down & sale of their datacenters, this was just one of many such servers they owned.
Is that something you do often, getting cheap gear like that? Smart move!
Not usually to this extent.
I don’t know enough about how Lemmy works. Can you have an active/passive cluster (physical or virtual) to assist in uptime for the instance?
Yes, can do active / active effectively. That’s basically stage 3 but it’s all on one box to keep costs down. We get software failure redundancy but not hardware.
The reason I ask is. Can I host a server for you to be a passive node to help out?
Ah thanks for the offer but there’s PII concerns there.
Ah, i didn’t know that. No problem. Just trying to help. Love the Lemmy community.
Probably out of context, but do you have any plans of adding other networks up fedecan? Like mstdn.ca?
And are there any plans for other services like Pixelfed, Friendica, or Peertube?
Probably out of context, but do you have any plans of adding other networks up fedecan? Like mstdn.ca?
We’re open to it, and it has a number of benefits, but we haven’t formally discussed with their team on what that might look like.
And are there any plans for other services like Pixelfed, Friendica, or Peertube?
Yes, we definitely want to spin up more things once we are settled. Pixelfed is near the front of that list, as well as Friendica.
We haven’t said no to any of them, but for example there isn’t as much of a need for us to spin up Mastodon since mstdn.ca exists. A lot of us have accounts on there too
That’s awesome! I can’t wait for it to grow. I’d love to help in any way I can.
What’s the average cost per user per year at this time?
Good question. Just going off the numbers on the main page side bar and doing some quick math, maybe about $1.10 per user per year.
That’s so much lower than I was expecting.
Do we have something like a week of fundraising or a pledge drive to get the word out on donations? $2 or $5 a year is very reasonable.
I’m not worried about it yet, we’re covering our costs as it is today with existing donations. I don’t want us to be like Wikipedia begging for money all the time.
lol that was the case study I had in mind to avoid
Wow that’s amazingly cheap! It doesn’t cost much to have digital independence.
What would be an ideal monthly contribution for lemmy.ca users? I’ve only done punctual donations so far. But I’m willing to do a monthly donation.
I think that’s just a personal decision.
Do you really feel you’re lacking in compute resources?
How does Lemmy scale with more active users?
Compute no, but memory yes. Lemmy is actually pretty lean and efficient, but 32gb is a bit tight for a few instances of it as well as postgres. We run multiple instances to reduce the impact when one stutters (not uncommon).
Upgrading to 64gb probably would have let us scale for the next year on the existing box, but I had this totally overkill hardware so might as well use it!
I’ve actually been investigating Postgres cluster configurations the past 2 weeks at work (though we’re considering CloudNativePG+Kubernetes on 3 nodes spanning two physical locations).
One thing I might recommend is to investigate adding a proxy like PgBouncer in front of the databases. This will manage request differences where write-queries must go to the primary, but read-queries may go to any of the replicas as well.
It should also better handle the recycling of short-lived and orphaned connections, which may become more of a concern on your stage 3, and especially on some stage 4.
PGBouncer is more of a connection pooler than a proxy.
Outside of the k8s ecosystem patroni with haproxy is probably a better option.
Pgbouncer is still good practice though because PG just can’t handle a high number of connections.
Ah yeah good call, thanks.
The new server is 😻
Thank you for all your work.






{kind=link}
{kind=link}